

Text mining et nuage de mots avec le logiciel R : 5 étapes simples à savoir
Le principe du nuage de mots est bas? sur une m?thode d?analyse de textes qui nous permet de mettre en ?vidence les mots-cl?s les plus fr?quemment utilis?s dans un paragraphe de textes. Le nuage de mots est ?galement appel? word cloud ou tag cloud en anglais. La proc?dure de cr?ation d?un nuage de mots est tr?s simple avec le logiciel R si vous connaissez les diff?rentes ?tapes ? ex?cuter. Le package tm (pour text mining) et le package wordcloud (pour g?n?rer le nuage de mots cl?s) sont disponibles dans R pour nous aider ? analyser des textes et de visualiser rapidement les mots-cl?s en nuage de mots.
L?objectif de ce tutoriel est d?expliquer les diff?rentes ?tapes pour g?n?rer un nuage de mots ? partir du logiciel R.
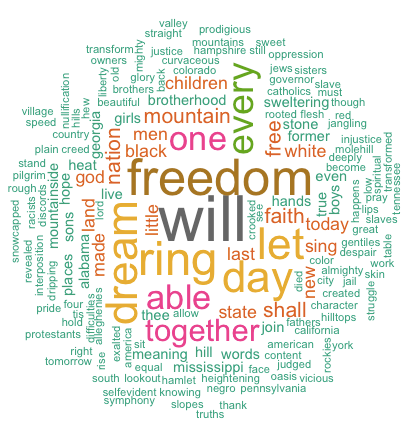
3 raisons pour lesquelles vous devriez utiliser des nuages de mots pour pr?senter vos textes
- Le nuage de mots est une m?thode puissante pour l?analyse de textes. Il ajoute de la simplicit? et de la clart?. Les mots-cl?s les plus utilis?s ressortent mieux dans un nuage de mots.
- Le nuage de mots est un outil de communication puissant. Il est facile ? comprendre, ? partager et est percutant
- Le nuage de mots est visuellement plus agr?able qu?une table de donn?es remplie de textes
Qui utilise les nuages de mots?
- Les chercheurs: pour la pr?sentation des donn?es qualitatives
- Les Marketers: pour mettre en ?vidence les besoins et les points d?insatisfaction des clients
- Les enseignants: pour soutenir des sujets essentiels
- Les politiciens et les journalistes
- Les r?seaux sociaux: pour collecter, analyser et partager les sentiments des utilisateurs
Les cinq principales ?tapes de la cr?ation d?un nuage de mots avec le logiciel R
Etape 1: Cr?ez un fichier texte
Dans les exemples suivants, je vais analyser le discours de Martin Luther King (?I have a dream?), mais vous pouvez utiliser n?importe quel autre texte :
- Copiez et collez le texte dans un fichier texte (par exemple: ml.txt)
- Enregistrez le fichier
Notez que, le texte doit ?tre enregistr? dans un fichier au format texte simple (.txt) en utilisant votre ?diteur de texte favori.
Etape 2: Installer et charger les packages n?cessaires
Les packages text mining (tm) et wordcloud sont n?cessaires.
Ils peuvent ?tre install?s et charg?s en utilisant le code de R ci-dessous:
# Installer
install.packages("tm") # pour le text mining
install.packages("SnowballC") # pour le text stemming
install.packages("wordcloud") # g?n?rateur de word-cloud
install.packages("RColorBrewer") # Palettes de couleurs
# Charger
library("tm")
library("SnowballC")
library("wordcloud")
library("RColorBrewer")Etape 3 : Exploration de textes
Charger le texte
Le texte peut ?tre charg? en utilisant la fonction Corpus() du package tm. Corpus est une liste de documents (dans notre cas, nous avons juste un seul fichier).
Dans l?exemple ci-dessous, j?ai charg? un fichier .txt disponible sur le site web STHDA. Vous pouvez utiliser n?importe quel fichier de votre ordinateur.
# Lire le fichier texte
filePath <- "https://www.sthda.com/sthda/RDoc/example-files/martin-luther-king-i-have-a-dream-speech.txt"
text <- readLines(filePath)
# Charger les donn?es comme un corpus
docs <- Corpus(VectorSource(text))La fonction VectorSource() se charge de la cr?ation du corpus de textes (ensemble de vecteurs de textes)
Le contenu du document peut ?tre consult? comme suit:
inspect(docs)La transformation du texte
La transformation du texte est effectu?e en utilisant la fonction tm_map() pour remplacer, par exemple, des caract?res sp?ciaux non utiles.
Remplacer ?/?, ?@? et ?|? avec un espace
toSpace <- content_transformer(function (x , pattern ) gsub(pattern, " ", x))
docs <- tm_map(docs, toSpace, "/")
docs <- tm_map(docs, toSpace, "@")
docs <- tm_map(docs, toSpace, "\\|")Nettoyage du texte
La fonction tm_map() est utilis?e pour supprimer les espaces inutiles, pour convertir le texte en minuscules, supprimer les ?mots vides? (stopwords en anglais). Il s?agit des mots tr?s courants dans une langue comme ?le?, ?la?, ?nous?, ?et?, etc.
La valeur de l?information de ces ?mots vides? est proche de z?ro en raison du fait qu?ils sont si communs dans une langue. La suppression de ce genre de mots est utile avant de poursuivre une analyse plus approfondie.
Pour la suppression de ces mots vides, les langues support?es sont: danish, dutch, english, finnish, french, german, hungarian, italian, norwegian, portuguese, russian, spanish et swedish. Le nom des langues est sensible ? la casse.
Je vais aussi vous montrer comment faire pour supprimer votre propre liste de mots du texte.
Vous pouvez ?galement supprimer des chiffres et ponctuations avec les arguments removeNumbers et removePunctuation.
Une autre ?tape importante de pr?paration du texte est de faire du texte stemming. Ce processus consiste ? r?duire les mots ? leurs racines. En d?autres termes, ce processus supprime les suffixes des mots pour les rendre simples et pour obtenir l?origine commune. Par exemple, le text stemming va r?duire les mots ?partir?, ?partant?, ?partons? ? la racine ?partir?.
Notez que le text stemming n?cessite le package ?SnowballC?.
Le code R ci-dessous peut ?tre utilis? pour nettoyer le texte :
# Convertir le texte en minuscule
docs <- tm_map(docs, content_transformer(tolower))
# Supprimer les nombres
docs <- tm_map(docs, removeNumbers)
# Supprimer les mots vides anglais
docs <- tm_map(docs, removeWords, stopwords("english"))
# Supprimer votre propre liste de mots non d?sir?s
docs <- tm_map(docs, removeWords, c("blabla1", "blabla2"))
# Supprimer les ponctuations
docs <- tm_map(docs, removePunctuation)
# Supprimer les espaces vides suppl?mentaires
docs <- tm_map(docs, stripWhitespace)
# Text stemming
# docs <- tm_map(docs, stemDocument)Etape 4: Construire la matrice des mots
La matrice des mots (term-documents matrix) est une table contenant la fr?quence des mots. La fonction TermDocumentMatrix() du package text mining peut ?tre utilis?e comme suit :
dtm <- TermDocumentMatrix(docs)
m <- as.matrix(dtm)
v <- sort(rowSums(m),decreasing=TRUE)
d <- data.frame(word = names(v),freq=v)
head(d, 10) word freq
will will 17
freedom freedom 13
ring ring 12
day day 11
dream dream 11
let let 11
every every 9
able able 8
one one 8
together together 7Etape 5: G?n?rer le nuage de mots
L?importance des mots peut ?tre illustr?e par un nuage de mots comme suit:
set.seed(1234)
wordcloud(words = d$word, freq = d$freq, min.freq = 1,
max.words=200, random.order=FALSE, rot.per=0.35,
colors=brewer.pal(8, "Dark2"))
Le nuage de mots ci-dessus montre clairement que les mots ?Will?, ?freedom?, ?dream?, ?day? et ?together? sont les cinq mots les plus importants dans le texte ?I have a dream? de Martin Luther King.
Les arguments de la fonction wordcloud sont :
- words : les mots ? dessiner
- freq : la fr?quence des mots
- min.freq : les mots avec une fr?quence en dessous de min.freq ne seront pas illustr?s
- max.words : nombre maximum de mots ? dessiner
- random.order : dessine les mots dans un ordre al?atoire. Si false, ils seront dessin?s par ordre d?croissant de la fr?quence
- rot.per : la proportion de mots verticaux sur le graphe
- colors : couleurs des mots du moins au plus fr?quent. Utiliser par exemple, colors =?black? pour une couleur unique.
Allez plus loin
Explorer les mots fr?quents ainsi que leurs associations
Vous pouvez voir les mots les plus fr?quents comme suit. L?exemple, ci-dessous, montre les mots qui sont fr?quents au moins 4 fois dans le texte :
findFreqTerms(dtm, lowfreq = 4) [1] "able" "day" "dream" "every" "faith" "free" "freedom" "let" "mountain" "nation"
[11] "one" "ring" "shall" "together" "will" Vous pouvez analyser l?association entre les mots (leur corr?lation) en utilisant la fonction findAssocs(). Le code R ci-dessous identifie les mots qui sont le plus fr?quemment associ?s ? ?freedom? dans le texte I have a dream :
findAssocs(dtm, terms = "freedom", corlimit = 0.3) freedom
let 0.89
ring 0.86
mississippi 0.34
mountainside 0.34
stone 0.34
every 0.32
mountain 0.32
state 0.32Table de la fr?quence des mots
head(d, 10) word freq
will will 17
freedom freedom 13
ring ring 12
day day 11
dream dream 11
let let 11
every every 9
able able 8
one one 8
together together 7Dessiner la fr?quence des mots
La fr?quence des 10 premiers mots est montr? ci-dessous :
barplot(d[1:10,]$freq, las = 2, names.arg = d[1:10,]$word,
col ="lightblue", main ="Most frequent words",
ylab = "Word frequencies")
Infos
Cette analyse a ?t? r?alis?e avec le logiciel R (ver. 3.1.0).
Show me some love with the like buttons below... Thank you and please don't forget to share and comment below!!
Montrez-moi un peu d'amour avec les like ci-dessous ... Merci et n'oubliez pas, s'il vous plaît, de partager et de commenter ci-dessous!
Recommended for You!





Click to follow us on Facebook:
Comment this article by clicking on "Discussion" button (top-right position of this page)
